


Glooko’s solution to help healthcare systems implement smoother RPM workflows
As Remote Patient Monitoring (RPM) services experience higher adoption especially with the expansion of reimbursement for such programs, opportunities to support proactive care in the diabetes space emerge.
Glooko provides care teams with the ability to remotely monitor and provide diabetes management services for people with diabetes without needing to visit the clinic. The goal is to broaden access to remote diabetes management and ensure continuity of care between patients and healthcare professionals and deliver a personalized, uncomplicated experience for people with diabetes.
As health systems implement RPM programs, a few common challenges arise:
- Some patients disengage with the digital health technologies that are required to run RPM programs, with the patient’s dropout risk being greatest during the first three months after onboarding to the program.
- For patients that disengage with digital health tools, care providers are unable to provide effective monitoring and coaching because they have insufficient data on their remotely monitored patients.
- Reimbursement for RPM services requires enough patient data to meet thresholds for CPT codes, and reimbursement is at risk for patients that disengage with their digital health tools.
Requirements for frequency and amount of patient data to meet RPM reimbursement criteria highlight the need for continued patient engagement. Therefore, understanding and targeting patient “dropout risk” (the likelihood of the patient dropping out of the RPM program) is essential for health systems to effectively run remote patient monitoring workflows.
Leveraging dropout risk to take timely action
To help health systems with the above challenges and support timely targeting of interventions in RPM programs, Glooko predicts patient dropout risk (the likelihood that the patient will drop out) up to 4 weeks prior to patient disengagement from the program. The feature gives health systems the opportunity to identify and selectively reach out to patients at highest risk of dropout in a timely manner, resulting in a smoother RPM experience that meets reimbursement criteria.
We offer the Dropout Risk insight through the “At-Risk” feature that is part of Glooko’s digital health platform for diabetes (Figure 1). A higher risk score for a patient corresponds to a greater probability of dropping out over the next 4 weeks. From there, health systems are able to easily identify patients at high risk of program dropout and intervene proactively.
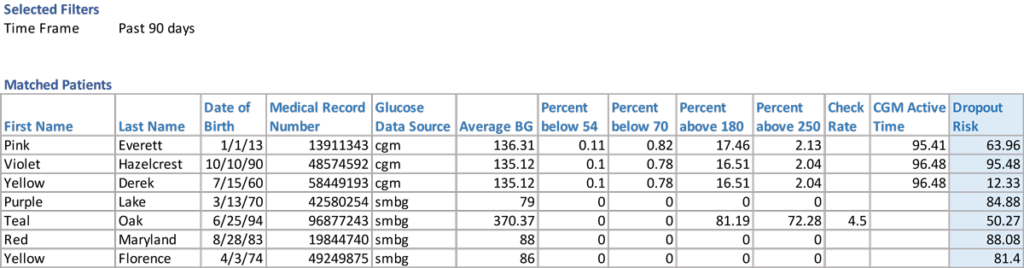
Figure 1. Predicted dropout risk scores offered through Glooko’s “At-Risk” feature.
Developing a machine learning model that predicts dropout risk
Glooko’s Dropout Risk feature predicts the probability that a patient will drop out in the next 4 weeks and updated predictions are available on a weekly basis. Dropout is defined as a patient who stops uploading their diabetes device(s).
We trained a machine learning (ML) algorithm that predicts, based on data from the 4 weeks prior to prediction, the probability that the user will drop out in the 4 weeks post prediction.
Building features and feature selection
To train our model, we used historical data over a 6-month period. We initially included 104 features (characteristics about the user) from three sources of data that consisted of demographics, diabetes outcomes, and mobile app engagement from the 4 weeks prior to prediction:
- Demographics information (e.g. type of diabetes, age) collected during user registration
- Diabetes outcomes (e.g. average glucose, hypo/hyperglycemia counts, reading frequency) derived from diabetes device data uploaded to Glooko
- Mobile app engagement data (e.g. app clicks)
We used feature selection to reduce the complexity of the model, make it more interpretable, and increase performance. To this end, we conducted Variance Inflation Factor (VIF) analysis to remove multicollinearity (i.e., features that were highly correlated with others). This resulted in a subset of 19 features that we used to train the machine learning model (Table 1).
Table 1.
Data features used to train the machine learning model
| DIABETES OUTCOMES AND ENGAGEMENT |
APP ENGAGEMENT | DEMOGRAPHICS |
| Hypoglycemia occurrences Hyperglycemia occurrences Average blood glucose Number of Glucose Checks |
Number of app clicks App features that were clicked Number of diabetes device uploads Days since last app activity Days since last device upload Number of active days on app |
Diabetes type Gender Age Tenure on Glooko Diabetes device type |
Model selection, interpretability, and feature directionality
While identifying patients of highest dropout risk is important (who is dropping out?), an interpretable machine learning model (whyare they dropping out?) is equally important to be able to understand and target patient dropout.
Leveraging our trained Gradient Boosting Algorithm, which performed better than six other ML models, we derived feature importance scores to find the strongest predictors of dropout, i.e., which patient characteristics highly affected dropout risk. The number of device uploads, the number of days since last device upload, and the number of glucose checks during the 4 weeks prior were the 3 features that influenced dropout risk the most (Figure 2).
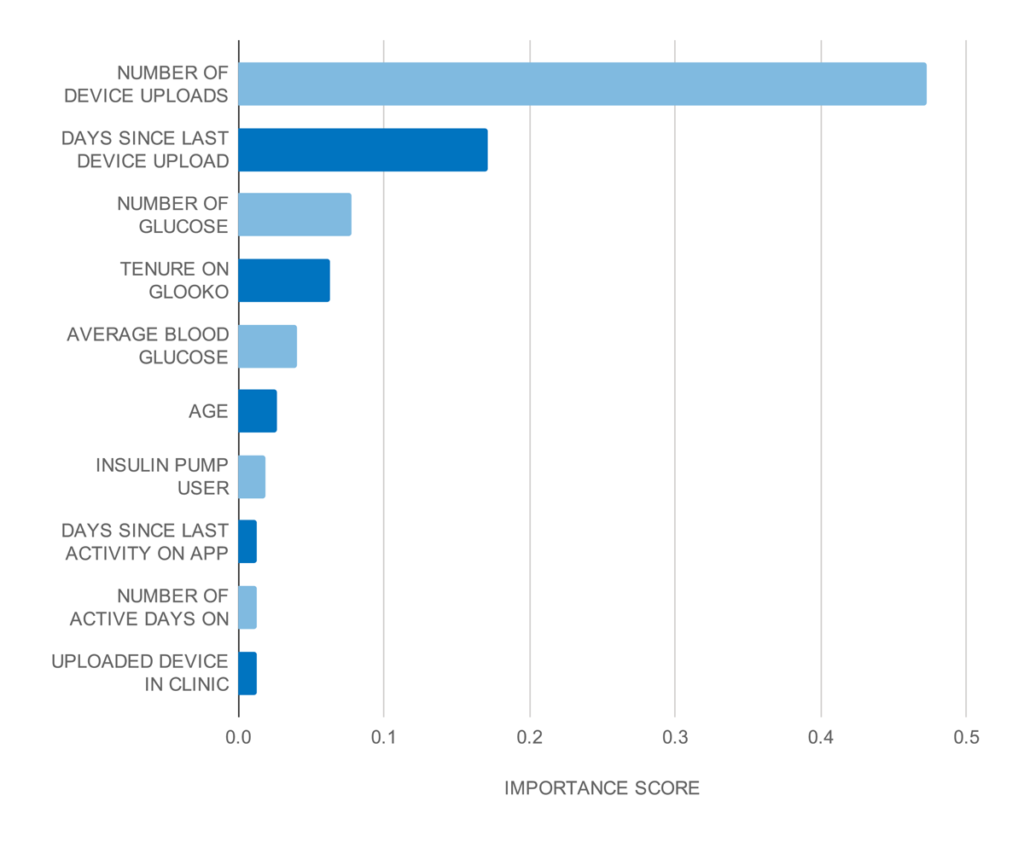
Figure 2.
Top 10 strongest predictors based on the gradient boosting classifier feature importance scores.
To find out the directionality of features, i.e., if a feature increases or decreases dropout risk, we trained a logistic regression model on the same dataset and derived feature coefficients.
Our analysis showed that a higher number of days since the last device upload increased dropout risk, while a higher number of device uploads and higher number of glucose checks both decreased dropout risk.
Model performance and validation
We performed out-of-sample validation, i.e., using data that was excluded from model training, to find algorithm performance metrics which are summarized in Table 2.
Model recall (sensitivity) was 81%, which means that the trained model correctly detected 81% of users that actually dropped out. With a precision of 68%, our model performed 1.35 times better than a baseline model that randomly predicts that a user will drop out.
Table 2.
Algorithm performance metrics on the test cohort
| PRECISION (Positive Predictive Value) |
RECALL (Sensitivity) |
SPECIFICITY | AUC |
| 0.68 | 0.81 | 0.59 | 0.78 |
We validated the model at different dropout risk levels and compared with the actual dropout rate for each level. Our risk predictions showed strong agreement with actual dropout rates. The figure below shows these comparisons at very low (0-20%), low (20-40%), medium (40-60%), high (60-80%), and very high (80-100%) risk levels.
For example, for users predicted to have very high dropout risk (80-100%), we found that the actual dropout rate for this cohort was 92.3%. Similarly, the actual dropout rate for those predicted to be at low risk (20-40%) was 27.6%.
| PREDICTED DROPOUT RISK |
ACTUAL DROPOUT RATE IN BIN |
| 0-20% (very low) | 8.00% |
| 20-40% (low) | 27.60% |
| 40-60% (medium) | 49.50% |
| 60-80% (high) | 71.00% |
| 80-100% (very high) | 92.30% |

Table 3 and Figure 3.
Model validation at different dropout risk levels.
References
Babikian S, Singh V, Clements MA. A Machine Learning Model Predicts Engagement with a Mobile Health (mHealth)-Based Remote Patient Monitoring (RPM) Program among Persons with Diabetes (PWDs). Diabetes 2020 Jun; 69(Supplement 1). https://doi.org/10.2337/db20-862-P
